Frequent errors during submission, and how to debug
Here we show common errors during the automated tests and how to fix them.
When you submit your method, it will automatically run on the fake data first (“PreFer_fake_data.csv”). Only if this check is successful, the method will run on the holdout set. Here we will be adding common reasons why your submission might fail to pass this automatic checks.
Note: always test your method locally on the fake data before submitting (e.g. apply your method to the fake data to see if the method produces predictions) and debug in case of errors. Here we will mostly focus on errors that you might still encounter during this automated check even if your method was working locally).
Checklist to avoid errors
We will be constantly updating this list based on the errors in submissions.
What to check to avoid errors:
- if at any point during preprocessing, you do one-hot encoding (create dummy variables), make sure that you do not include columns in the model that will not exist in the preprocessed dataset because there are no such values in the holdout data. You can check which values of categorical variable are present in the holdout data using the fake data. Categorical variables in the fake data only include values that are present in the holdout data. And vice versa: check if there are any values of the categorical variables included in your model, which are not present in the training data but are present in the holdout data. If there are, you need to add these columns to the model
- if you recode continuous variables into categorical, make sure that the categories are not too small (e.g. there is no category which includes only a few people); otherwise, there is a risk that some category will be missing in the preprocessed holdout data which can result in an error. Remember that not all values of continuous variables that are in the holdout data are included in the fake data (to keep the fake data at a manageable size). The minimum and maximum values of continuous variables are the same as in the holdout data
- make sure that you’ve edited the function clean_df in submission.py/submission.r so that it can be applied to the holdout data. For example, inside this function, you use the argument (df), not a custom variable name you used during the preprocessing of the training data
- make sure you don’t load the training data in the submission.py/submission.r. It shouldn’t be loaded because the clean_df function will be applied to the holdout data which will be provided as the argument to this function
- make sure you are not using the file with the outcome in the clean_df function; if you need to select only observations for which the outcome is not missing, you can use the variable ‘outcome_available’ (described here)
- (for Python users) the environment name in environment.yml is not changed - it is ‘eyra-rank’
- (for Python users) add only the packages that you are using to the environment.yml, don’t add all their dependencies
- all additional files that you are using (e.g. the codebooks, your custom scripts with functions, etc.) are added to your repository (root folder). If you are using R, additionally you need to check the ‘r.Dockerfile’ file, which is in your repository: check if the line ’COPY *.csv /app’ is there. If not, please add it after the other lines with ‘COPY’.
- all the files needed for the submission are in the repository. It’s easier not to delete anything from the repository. The most important files are submission.py/submission.r, settings.json (has information about whether you use python or R), environment.yml/packages.R, training.py/training.r, description.md, model.joblib/model.rds (or the model in another format), run.py/run.r, python.Dockerfile/r.Dockerfile, score.py
- you haven’t deleted any functions from submission.py/submission.r. Even if you don’t have to change the ‘predict_outcomes’ function, you shouldn’t delete it
- your ‘predict_outcomes’ function produces predictions in the format of 1s and 0s, not e.g. probabilities. If your model by default produces predictions in another format, don’t forget to update the ‘predict_outcomes’ function
- if you are using R, you’ve changed the settings.json file as explained here
- all packages that you are using are added to the environment.yml or packages.R
How to find out if your method passed automatic checks
You can see it on the “Actions” tab in your own github repository. Make sure to allow Github Actions: go to the “Actions” tab and click “I understand my workflows, go ahead and enable them.”
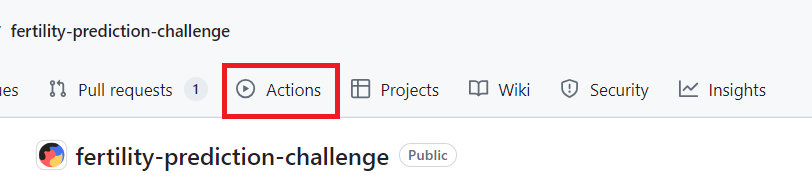
After you update your repository, you will see on this page whether your method passed automatic checks or not.
If you cannot enable Actions, it might mean that you haven’t forked the repository. Make a copy of the template repository by forking and cloning as explained here, not by creating a new repository.
How to find the error message
Click on the failed “run”. You’ll see a message there.

You can also click on “test” and view more detailed information about the error and the stage at which it occurred.
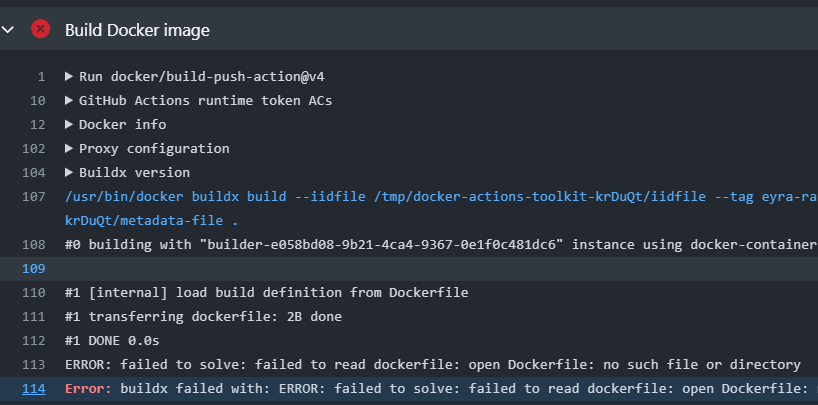
Common errors
This error appears if you are using one programming language for submission, but the “settings.json” indicates a different language. Most likely you are using R, but you haven’t changed the settings. The default set-up is Python; if you would like to use R, go to settings.json and change {“dockerfile”: “python.Dockerfile”} into {“dockerfile”: “r.Dockerfile”}.

This error occurs if you added new variables to the model, but did not change the “clean_df” function in the submission script accordingly.
This error occurs if you added new variables to the model and updated the “clean_df” function in submission script accordingly, but the model is not updated.
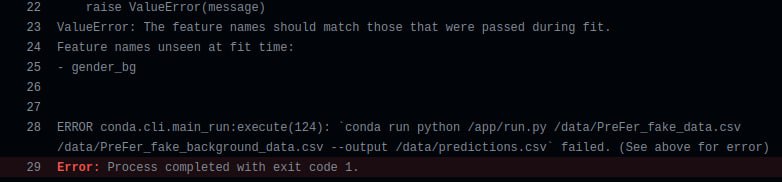
This error occurs if you are using an (R) package which is not listed in “packages.R” file. Add this package to this file.
Photo by Timothy Dykes on Unsplash