The task, goal, and research questions
The goal of the data challenge is to assess the current predictability of individual-level fertility and improve our understanding of fertility behaviour.
Welcome to the website of the Predicting Fertility data challenge (PreFer). The aim of the challenge is to measure current predictability of fertility outcomes in the Netherlands to advance our understanding of fertility
The challenge has now ended. We are analysing the results and will be sharing updates on this website. If you have questions about PreFer, please check the FAQ or contact us
Deadlines for submissions:
Fertility is widely studied in diverse disciplines due to its importance to individuals and societies. A lot of factors have been identified that are related to fertility outcomes. Yet these important factors only explain a fraction of the variation in fertility outcomes and we are unable to explain even their short-term changes. What do we miss?
This data challenge can potentially advance our understanding of fertility behavior and improve social policies and family planning in several ways. Measuring how well different factors and models can predict fertility outcomes for new cases will show which factors are more important. It can narrow down a scope for potential interventions and help people reach their desired family size. Comparing and interpreting different models submitted to a data challenge (e.g. theory- and data-driven) can identify new factors currently overlooked by the theories of fertility and highlight the gaps in current knowledge (e.g. important interactions or non-linear effects).
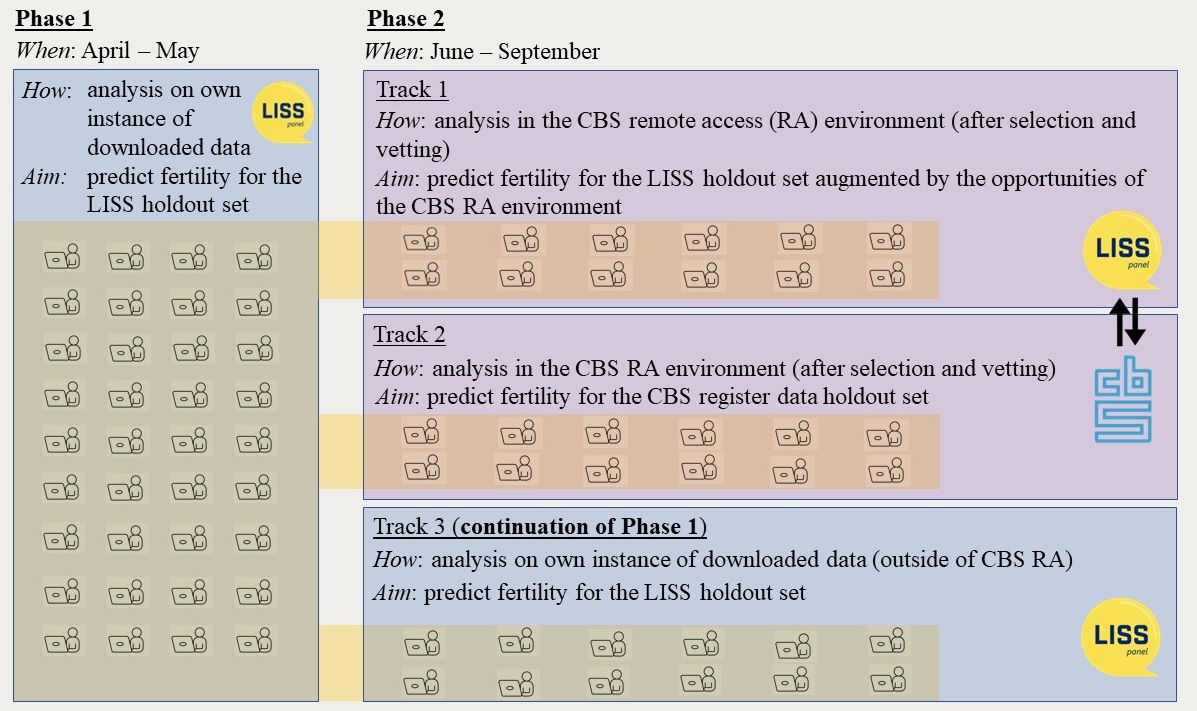
*Only a selection of participants will get an opportunity to work with the register data in Phase 2 of the data challenge. For these participants the costs of access to the register datasets will be covered by ODISSEI. See conditions for accessing the register data here.
Fill out this form to apply for participation in the data challenge. You can find the details about applications here. The application deadline is March 24th.
Use any method you’d like to train a predictive model using training data we provide. The models will be then evaluated on a holdout set based on the F1 score. More information about the phases of the data challenge can be found here.
Submit your model (in Phase 1) or predictions (in Phase 2). The link the submission platform with all the instructions how to submit will appear on this website soon.
This research was approved by the ethical committee of sociology at the University of Groningen (SOC-2425-S-0002).