‘Above all else, show the data’ - workshop Schiermonnikoog
January 27, 2026
Welcome
Welcome to this Data Visualisation workshop at the Schiermonnikoog Life History Theory Course. This workshop helps you in making graphs in R via ggplot2 and hopefully drives the point home that, above all else, show the data. ggplot2 is a visualization package for R, written by Hadley Wickham (Wickham 2016), and it is simply fantastic. At lightning speed, we’ll first cover R and RStudio, before we go on to learning how to visualize our data (beautifully) in R. You can switch to different topics using the navigation bar on the left.
Just to give you a glimpse of the amazingness of ggplot, see what a few lines of code in R can produce:
Above all else, show the data
In his book The Visual Display of Quantitative Information (1983), visual artist Edward Tufte “Above all else, show the data”. This quote has always resonated with me. Showing people all the data, allows insights but also scrutiny. Most graphs problematically hide most of the data (e.g., by showing only means). It is my strong belief that the replication crisis would not have been as severe, if our cultural norms of doing science included the practice of visualisation in which all or at leat most of the data are shown.
Why are visualizations important?
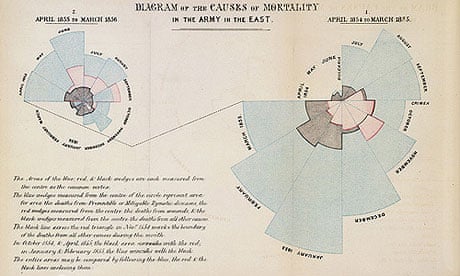
Graphs can change the world, as Florence Nightingale showed:
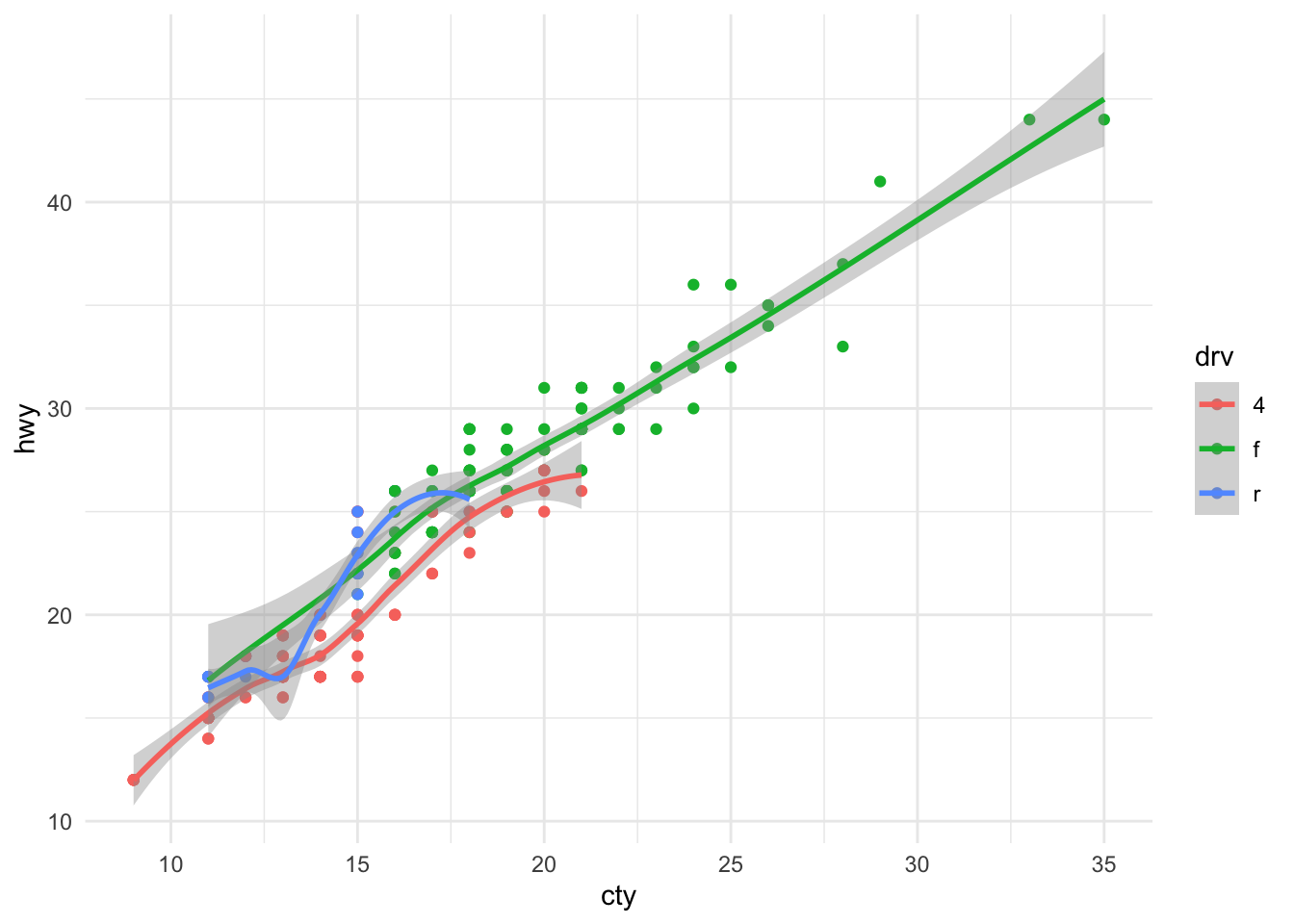
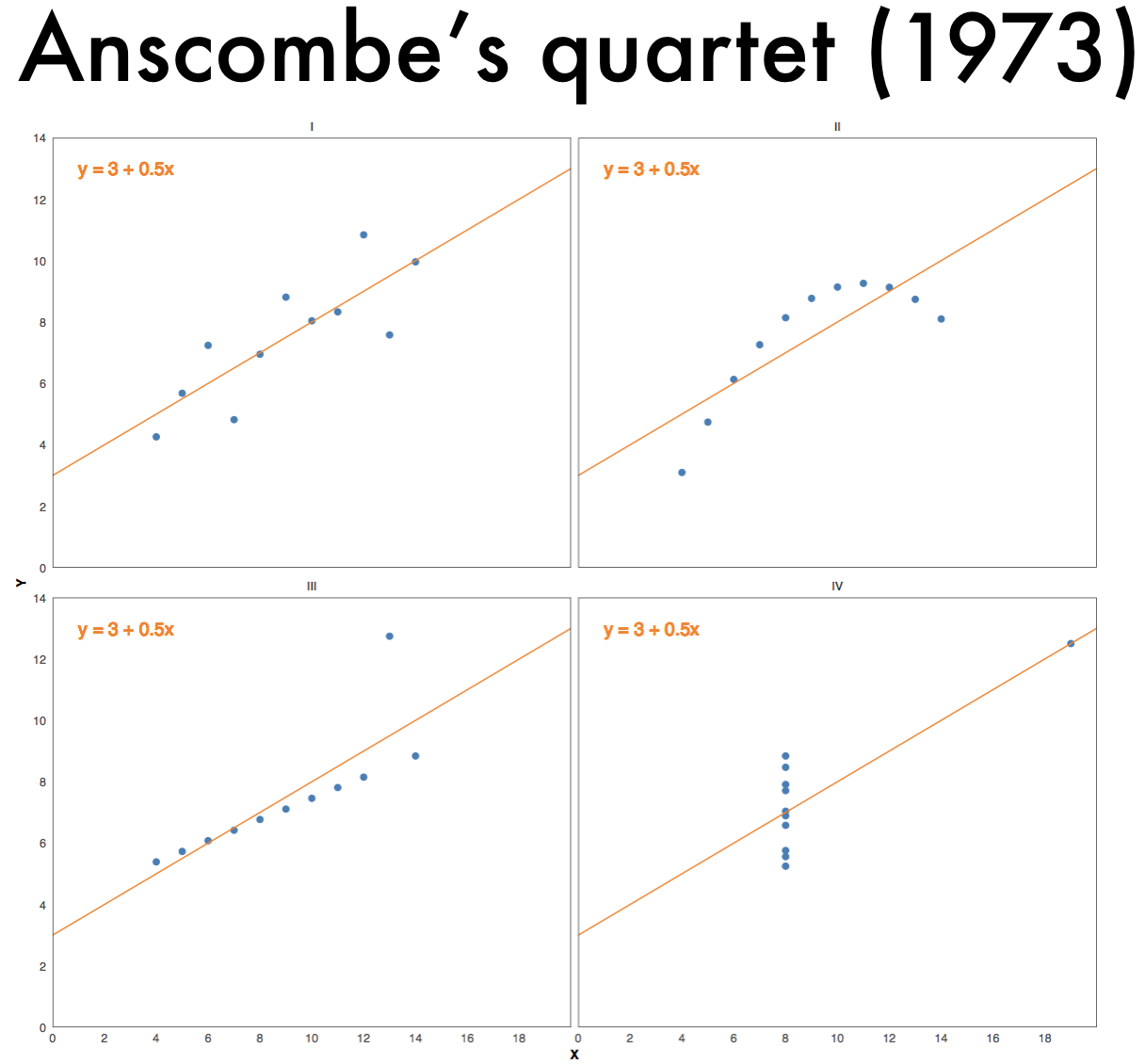
The importance of visualizations is further evident from Anscombe’s quartet:
And from the datasaurus dozen:
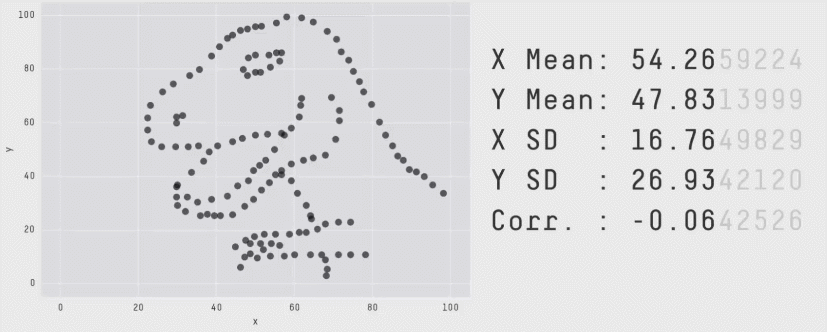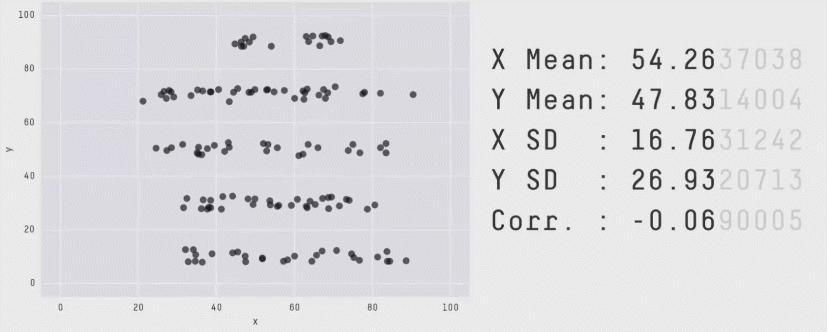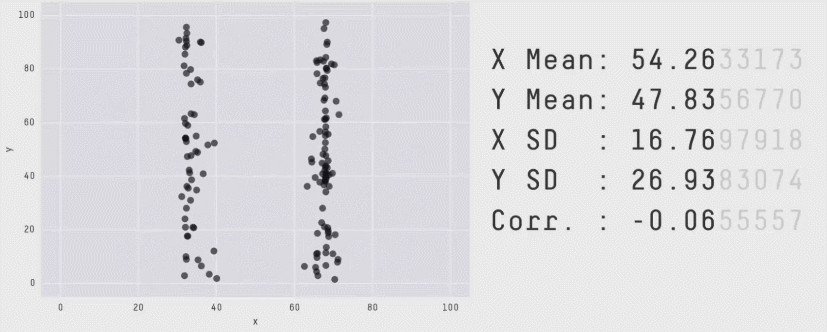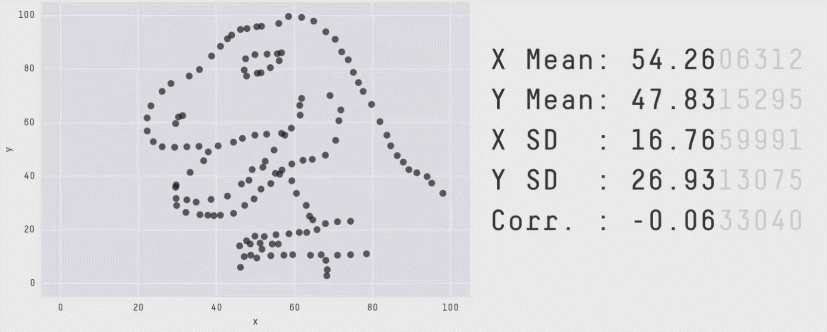
And from:
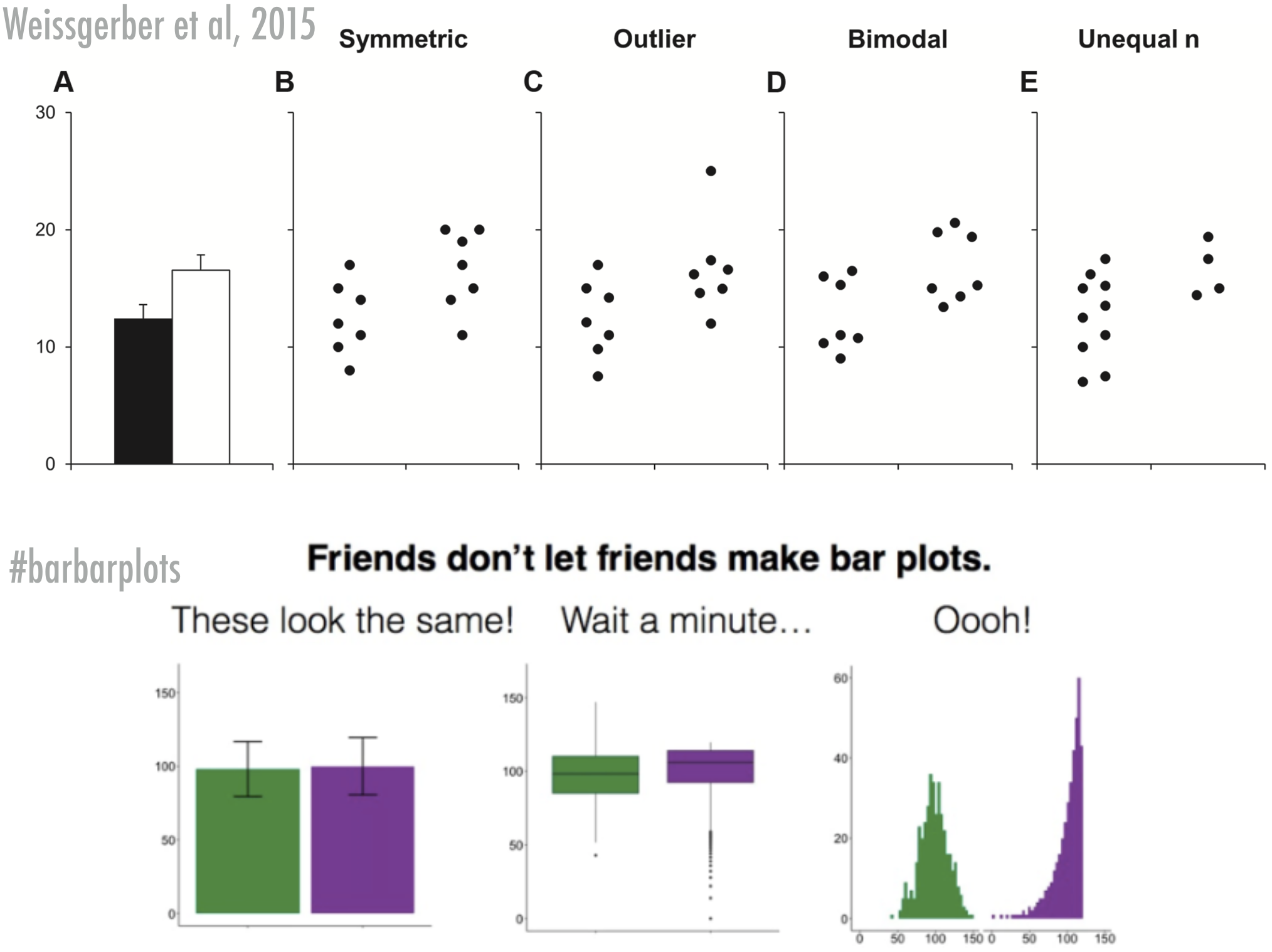
Why R?
Some reasons to use R:

You can easily generate stuff:
# Flipping a coin ten times
sample(c("Head", "Tails"), size = 10, replace = TRUE, prob = c(0.5, 0.5))## [1] "Head" "Head" "Head" "Tails" "Tails" "Head" "Head" "Tails" "Tails"
## [10] "Head"You can do ‘standard’ analysis, like linear regression:
##
## Call:
## lm(formula = hwy ~ cty + drv, data = mpg)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.7830 -0.9041 -0.3083 0.8973 5.0223
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.99883 0.46622 4.287 2.66e-05 ***
## cty 1.19859 0.03087 38.826 < 2e-16 ***
## drvf 2.22365 0.27027 8.227 1.42e-14 ***
## drvr 2.12501 0.33314 6.379 9.70e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.494 on 230 degrees of freedom
## Multiple R-squared: 0.9379, Adjusted R-squared: 0.9371
## F-statistic: 1157 on 3 and 230 DF, p-value: < 2.2e-16You can also do fancy “state-of-the-art” analysis stuff, for example:
- network analyses
- mixed models
- missing data imputation
- bayesian analyses
- making statistical webapplications
You’ll learn about the wonderful world of coding:
passed_the_test <- function(grade) {
if(grade > 5.5){
print("You passed the test")
}
else {
print("You failed the test")
}
}
passed_the_test(8)## [1] "You passed the test"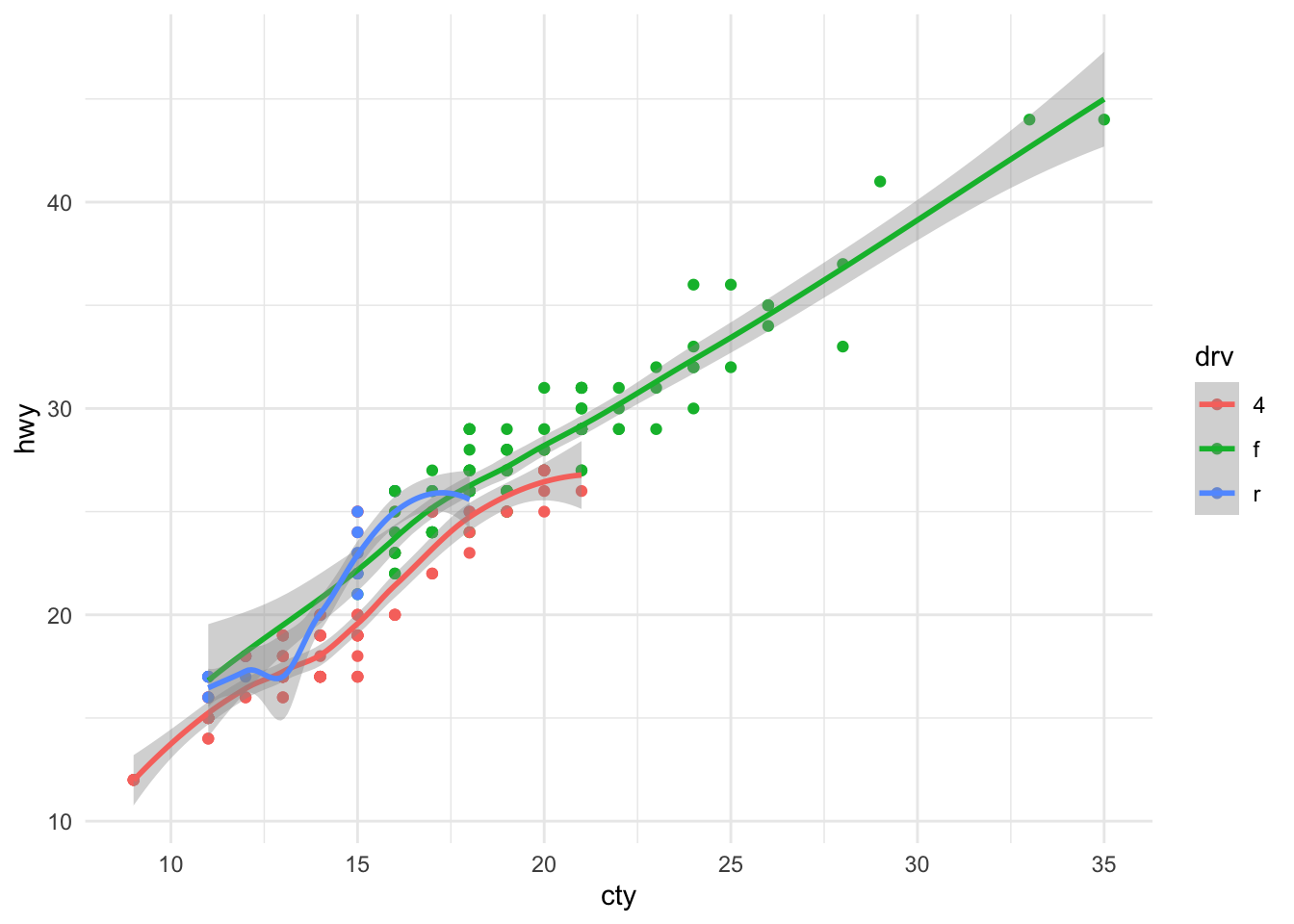
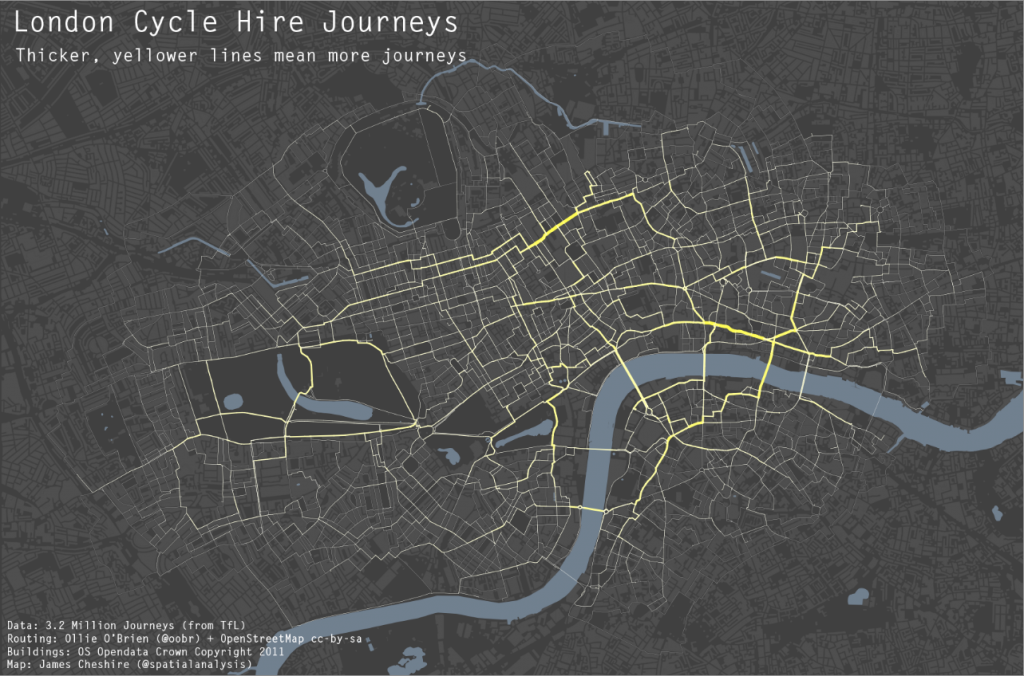 Source:
Source: 